2026美加墨世界杯(中国) 光轮智能与谷歌、英伟达共同界说物理AI仿真模范


机器之机杼剪部
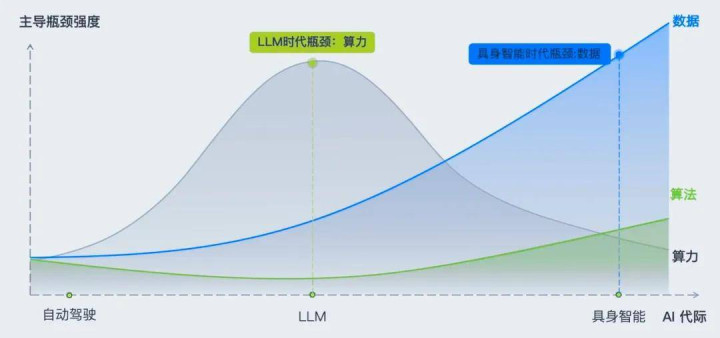
昔时十年,AI 卡的是算力;畴昔十年,物理 AI 卡的是数据。而数据的前提,是仿真。
莫得可鸿沟化的仿真寰球,就莫得可鸿沟化的机器东谈主数据;莫得长入的仿真模范,就不会有真确的物理 AI 生态。
仿真,正在成为物理 AI 时期的 CUDA。
CUDA 也曾把 GPU 盘算推算变成 AI 时期的长入底座。今天,仿真确成为物理 AI 时期新的模范层。
物理 AI 的核心瓶颈也曾变了
回望昔时的本领演进,每个阶段王人有我方的要津瓶颈。
大谈话模子时期,这个瓶颈是算力。非论是闭源的 GPT、Claude,如故开源的 Llama、Qwen、DeepSeek,这条赛谈的核心命题永恒只好一个:怎样用更多算力、在更大数据集上跑通 Scaling Law。算力的天花板在那边,模子智商的鸿沟就在那边。
守旧这一轮波涛的底层基础体式,恰所以 CUDA 为代表的长入盘算推算模范。CUDA 把 GPU 从图形盘算推算用具变成 AI 时期的通用盘算推算底座,也让大模子锤真金不怕火第一次领有了可鸿沟化调用的盘算推算基础体式。谁掌抓算力进口,谁就领有时期红利。
但进入物理 AI 时期,核心瓶颈正在从 “算力” 转向 “数据”。
昔时的大模子,本色上是用互联网语料学习东谈主类寰球;而物理 AI,需要学习真什物理寰球。谈话模子学习的是翰墨之间的联系,机器东谈主学习的则是力怎样传递、构兵怎样发生、动作怎样完了、寰球怎样反馈。
这意味着,物理 AI 所需要的数据,不再是互联网中自然存在的信息,而是必须在 “可交互、可实施、可考据” 的物理环境中被系统性生成。
数据的窘境,来自机器东谈主学习面容的根底各异。斯坦福教诲李飞飞曾在谈及机器东谈主智能与传统机器学习的各异时指出:“把数据带入机器东谈主锤真金不怕火,远比集中图片贫窭得多。” 机器东谈主模子要学会抓取、搬运、操作、行走,需要的不是静态图像,而是巨额覆盖真什物理交互的高质地行动数据。
这类数据无法像网页文本一样从互联网爬取,也无法通过简便扩大算力虚拟生成。自动驾驶尚有 “影子模式”:几百万辆量产车每天在真实谈路上行驶,司机的每一个操作王人不错成为自然监督信号;机器东谈主并莫得这么的基础体式。
也正因如斯,李飞飞进一步提议,不错用巨额仿真数据锤真金不怕火机器东谈主 “大脑”,再用更少许的真实数据弥合通往履行寰球的差距。换句话说,机器东谈主数据不是现成存在的互联网语料,而必须在可交互、可实施、可考据的环境中被系统性分娩出来;莫得锻真金不怕火的仿真体系,就莫得鸿沟化的锤真金不怕火数据,也就莫得具身智能的延续迭代。
除了数据数目,数据质地雷同要津。昔时指摘数据质地,通常联念念到告成完成任务的样本;但物理 AI 更需步骤路失败 —— 物体为什么滑落,动行动什么失稳,构兵为什么偏离预期。只好束缚走漏问题、纠错反馈,模子才可能从数据中真确得回学习信号。
因此,数据背后还有一个同等垂死却更掩饰的瓶颈:评测。
大模子时期的评测相对锻真金不怕火:锤真金不怕火吃亏是可靠的优化信号,模范化基准(MMLU、HumanEval 等)能平直响应模子智商进展。但在物理 AI 领域,这套逻辑失效了。锤真金不怕火吃亏的下落与实验室 Demo 的告成,已难以全面响应模子在真实环境中的轮廓智商;今天跑通的动作,换一个灯光、换一个物体名义,可能就失效了。
问题的核心在于:机器东谈主的锤真金不怕火与评测,本色上王人需要在适宜真什物理规定的环境中反复实施。但真实寰球不行无尽重置、不行大鸿沟并行,也难以系统性构造失败场景。莫得长入、可复现、可并行、可量化的评测体系,数据就很难有用蛊卦锤真金不怕火,模子也无法知谈我方在那边失败,更无法定向补凑数据、擢升智商。
因此,仿真不再是缓助用具,而是物理 AI 数据分娩与智商评测的前提条目。谁能构建更大、更快、更真实的仿真寰球,谁就同期掀开了数据分娩和智商评测两谈门,也就掌抓了通往通用具身智能的钥匙。
仿真
海外巨头争抢的物理 AI 策略高地
要是说上述判断还停留在表面层面,那么昔时十几年海外巨头的一系列动作早已用真金白银作念出了表态。他们通过收购、开源、孵化、自研,不遗余力地要把仿真智商镶嵌到我方的机器东谈主本领栈与生态模范中。
NVIDIA 早在 2008 年就收购了那时最主流的物理引擎 PhysX,并深度绑定自家 GPU 硬件,将其冉冉从游戏物理用具演进为 Omniverse 中的高精度仿真内核,成为 Isaac Sim 等机器东谈主平台的核心物理基础体式。
Google DeepMind 在 2021 年收购了 MuJoCo—— 此前它已是机器东谈主和强化学习圈的标配用具,成为论文、基准测试、开源代码的默许选项。由此,Google 铿锵有劲地拿到了统统机器东谈主学术界的用具链主导权。
Drake 孵化自 MIT CSAIL,后被 Toyota Research Institute(TRI)承袭,成为高的确能源学仿真的可蔓延底座;Bullet 则跟着创始东谈主的入职而与 Google 生态完了深度绑定。
Disney Research 则走了一条自研阶梯:孵化出专攻闭链机构与顶点工况畅通求解的仿真引擎 Kamino,专攻非模范构型下怎样踏实耸立和畅通,从而惩办交易化机器东谈主落地的高频痛点。
这些举措并非就怕,而是寰球顶级机构在仿真赛谈上特意志的策略卡位。昔时行业合计,仿真仅仅一个工程用具;但今天寰球巨头真确争夺的,也曾不是 “谁的引擎更快”,而是谁能界说寰球怎样被建模、物理怎样被抒发、数据怎样被生成、智商怎样被评测、机器东谈主怎样被锤真金不怕火。
因为谁界说仿真,谁就界说了机器怎样清醒履行寰球。这也曾不是用具之争,而是寰球界说权之争。
问题也随之出现:这些求解器耐久漫步在不同体系中,物理抒发、钞票模范、锤真金不怕火接口和评测历程彼此割裂。物理 AI 需要的,不是更多单点用具,而是一个能把这些智商整合进吞并架构的核心引擎。
Newton
寰球物理 AI 基础体式第一次走向长入
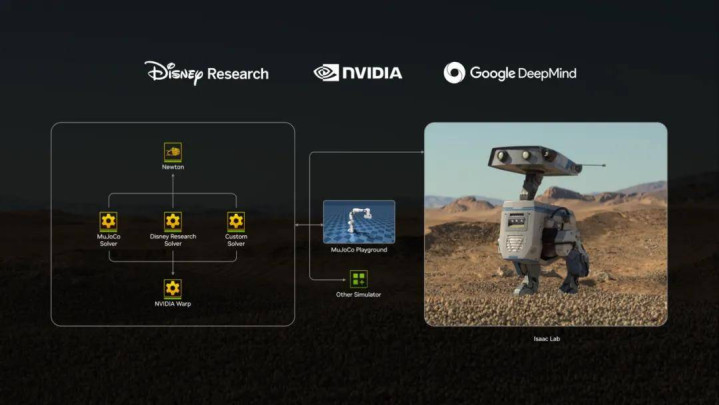
Newton 应时而生。
这不是一次世俗的开源发布,而是寰球物理 AI 基础体式第一次运行走向长入。昔时十几年,GPU 并行盘算推算、高精度构兵能源学、复杂机构求解、强化学习仿真、工业级机器东谈主考据,永恒漫步在不同体系中。Newton 第一次尝试把这些智商放进吞并个通达架构中。
它念念长入的是物理 AI 的底层寰球模子。
2025 年 9 月,NVIDIA、Google DeepMind 与 Disney Research 臆想开源物理仿真引擎 Newton Beta 版。它不是某一家公司的单点开源尝试,而是三家寰球顶级机构参预数百名工程师与商讨员、历时近两年延续征战,将各自最强的仿真智商放进吞并个通达架构中的效能。
NVIDIA 孝敬的是 GPU 原生加快、Warp 框架与 Isaac 生态。昔时十几年,NVIDIA 延续鼓励 GPU 从图形盘算推算走向通用盘算推算,再走向 AI 锤真金不怕火与物理仿真。到了 Newton,这套智商被进一步延长到机器东谈主学习场景:高并行、可蔓延,并可与当代 AI 锤真金不怕火基础体式深度联结。
Google DeepMind 带来的是 MuJoCo 在机器东谈主学习与高精度构兵能源学上的耐久积贮。MuJoCo 曾是机器东谈主强化学习和狂放商讨中最垂死的仿真用具之一,而 Newton 将这一套高精度能源学智商迁徙到 GPU 原生框架中,使其大致守旧更大鸿沟的并行锤真金不怕火和评测。
Disney Research 则将 Kamino 等仿真智商纳入其中。与模范机器东谈主形态不同,Disney 耐久濒临的是闭链机构、复杂结构、非模范构型与顶点工况下的畅通狂放问题,这使其在复杂机构踏实求解上变成了专有积贮。Newton 将这一齐线接收进长入架构,使机器东谈主仿真不再局限于传统刚体系统,而是进一步覆盖复杂机构、柔性材料与多物理交互。
也等于说,Newton 完了了 GPU 并行盘算推算、高精度构兵能源学、复杂机构求解与机器东谈主学习生态第一次在吞并个开源架构中完了系统性汇合。
模块化架构、GPU 原生加快、自动微分智商与跨生态和解机制,使 Newton 不仅仅一个物理引擎,更像是面向物理 AI 锤真金不怕火、评测与部署的长入仿真底座。
这些本性,使 Newton 从出身之初就站在了物理 AI 基础体式的要津位置。
值得见原的是,在这个由寰球顶级机构共同组成的物理 AI 仿真基础体式河山中,中国公司第一次出当今核心坐标上。
中国公司第一次
进入寰球物理 AI 模范界说层
本年三月,光轮智能线路受邀行动核心蛊卦委员加入开源 GPU 加快物理引擎 Newton,在要津具身仿真本领方朝上阐述主导作用,2026美加墨世界杯(中国)并与 NVIDIA、Google DeepMind、Disney Research, 共同引颈鼓励下一代开源物理 AI 仿真模范。
同期加入的还有 Toyota Research Institute (丰田商讨院),所带来的高的确能源学仿真的可蔓延软件底座 Drake ,进一步拓展了 Newton 的本领智商。
第一次,中国公司以核心共建者身份进入寰球物理 AI 仿真基础体式模范的界说层:昔时二十年,操作系统生态由 Microsoft 与 Apple 界说,出动生态由 Apple 与 Google 界说,AI 锤真金不怕火框架与盘算推算模范由 NVIDIA 与 Google 等巨头主导。而今天,物理 AI 的仿真模范终于运行有了中国公司的核心参与。
光轮加入 Newton TSC,是凭借全栈自研的 “求解—测量—生成” 三位一体本领平台。
领先,依托自研求解器与物理测量体系,主导 Newton 引擎核心智商的延续演进,包括求解器的物理考据与系统性标定、构兵建模与多物理场智商优化,以及仿真效能与真实寰球一致性的延续擢升。
其次,围绕 SimReady 体系,鼓励仿真钞票在物理属性模范、数据体式、接口模范、考据历程与评测体系等方面的进一步长入,完善下一代仿真寰球模范。
第三,依托物理测量工场与钞票生成体系,延续擢升鸿沟化 SimReady 寰球供给智商,构建高保真、可复用的仿真钞票与场景库,为寰球征战者提供可平直使用的仿真资源。
求解、测量、生成三者合在一谈,组成从物理建模、引擎考据到工程落地的完好闭环,这使 Newton 不仅能算,况且可考据、可复用、可鸿沟化进入真实工业历程。

也正因此,光轮成为 Newton TSC 核心共建模式中独逐个家中国公司。这秀气着其在物理 AI 底层本领领域的智商与影响力,得回了海外生态的线路认同。
事实上,光轮在海外开源生态中的布局远不啻于 Newton。
此前,光轮智能已臆想 NVIDIA 开源发布 Isaac Lab-Arena 机器东谈主策略评测基准框架,鼓励具身大模子评测走向可复现、可蔓延、可鸿沟化;自研 LeIsaac 仿真平台被 Hugging Face 官方文档收录,成为寰球征战者进入具身仿真的模范工程框架;联手 World Labs,用 RoboFinals 惩办寰球模子评测难题;臆想通义千问,通过 RoboFinals 共建可复现、可会诊的工业级评测闭环,鼓励具身智能评测从学术 benchmark 走向工业级基础体式。
从底层物理引擎,到征战者平台,再到评测框架与工业级闭环,光轮智能参与的并不是一个个一身名目,而是一条了了的生态旅途:底层物理引擎负责 “寰球怎样运行”,仿真平台负责 “征战者怎样使用”,评测框架负责 “模子怎样被权衡”,工业级评测闭环则负责 “智商怎样延续迭代”。
这条生态旅途的价值也曾在商场中得到考据。今天,光轮智能已成为寰球物理 AI 仿真与数据基础体式的垂死提供方,功绩寰球全部前五的寰球模子团队;海外主流具身智能团队中,逾越 80% 的仿真钞票与合成数据来自光轮。
在这条旅途上,光轮智能的变装发生变化:它不仅仅为头部模子团队提供仿真钞票与合成数据,更是在引颈构建物理 AI 时期的开源基础体式、征战者平台与评测模范。
中国公司第一次以核心本领共建者的身份,进入寰球物理 AI 仿真基础体式模范变成的要津位置。

寰球物理 AI 仿真 Top 5 众人天团
再看 Newton TSC 的东谈主员组成,可谓能手云集。

Miles Macklin Ph.D.(NVIDIA)NVIDIA 仿真本领高档工程总监,Warp 框架的臆想创造者。要是说 Newton 的速率上风有一个本领起源,等于 Macklin 和他的团队十几年来在 GPU 并行物理仿真上的积贮。
Yuval Tassa Ph.D.(Google DeepMind)机器东谈主仿真团队负责东谈主,MuJoCo 臆想创始东谈主。他惩办了 MuJoCo-Warp 的交融问题,让 MuJoCo 的物理精度在 GPU 上新生。Tassa 代表的是机器东谈主学界最核心的一条高精度仿真旅途。
谢晨 Ph.D.(光轮智能)光轮智能创始东谈主兼 CEO,曾任 NVIDIA 及 Cruise 自动驾驶仿真负责东谈主,耐久鼓励仿真与合成数据在自动驾驶和物理 AI 中的产业化落地。海外首创将生成式 AI 融入仿真,主导竖立光轮“求解—测量—生成”三位一体全栈自研仿真本清醒线。
Moritz Bächer Ph.D.(Disney Research)Disney Research 负责东谈主。Disney 的主题乐土可能是寰球对文娱机器东谈主要求最无情的环境,Kamino 求解器等于在他辖下出身的。
Michael Sherman Ph.D.(TRI) 是机器东谈主仿真基础体式领域的老兵。行动 TRI 机器东谈主仿真的核心负责东谈主之一,其功绩轨迹横跨 SD/FAST、Simbody、OpenSim、Drake 等多代要津仿真平台。
和这四位寰球仿真领域的核心奠基者比拟,谢晨博士的专有之处在于:他不是从单一求解器、单一学术体系或单点工程模块中走来,而是在自动驾驶与物理 AI 两代产业波涛中,延续主导仿真基础体式的工程化、鸿沟化与系统化落地。
他先后在 Cruise 和 NVIDIA 主导自动驾驶仿真体系成立,在 L4 自动驾驶一线考据了仿真与合成数据对算法迭代的价值,也在寰球仿真基础体式从自动驾驶时期走向物理 AI 时期的承担了要津变装。
在这一过程中,谢晨博士变成了分手于传统仿真众人的系统性视角:仿真不是一个求解器、一套用具链,或一个用于测试的虚拟环境,而是一套连气儿数据生成、模子锤真金不怕火、智商评测与真实部署的完好栽植系统。
自动驾驶时期,仿真主要功绩于视觉感知、场景回放与讲求测试;进入机器东谈主与物理 AI 阶段,仿真还必须惩办构兵、力传递、材料形变、动作失败等真什物理交互问题,并守旧模子在可复现、可鸿沟化的环境中延续学习。
2023 年,光轮智能的创立恰是要把这一判断系统化为可落地、可委用、可鸿沟化的全栈仿真基础体式。光轮所构建的不是单点仿真用具,而所以求解、测量、生成、锤真金不怕火、评测与部署为核心的完好闭环,连续引颈仿真从 “缓助考据用具” 走向物理 AI 的核心分娩系统。
因此,他加入 Newton TSC,不仅仅个东谈主入选,而是中国力量初次以核心构建者身份进入寰球物理 AI 基础体式的核心坐标。
仿的确物理 AI 时期的 CUDA
昔时十年卡算力,畴昔十年卡数据。而数据的前提,是仿真。
2006 年,NVIDIA 发布 CUDA。在那之前,GPU 仍主要被视为图形盘算推算用具,世俗征战者念念调用其并行盘算推算智商,门槛极高。CUDA 把 GPU 的盘算推算智商抽象成一套模范接口,闪征战者不错鸿沟化调用。
CUDA 告成的要津,在于它在要津窗口期同期完成了三件事:建立长入底层模范,让碎屑化算力不错被长入调用;构建 cuDNN 等一整套用具链,把底层算力翻译成征战者能平直调用的分娩力;通达生态,让这套模范变成跨场景、跨征战者、跨模子锤真金不怕火历程的普适性。
今天,物理 AI 正处在相似的历史节点。大模子时期,CUDA 界说的是 “怎样调用盘算推算”;物理 AI 时期,仿真要界说的是 “怎样生成寰球”,因为机器东谈主需要的是更多可交互、可实施、可评测、可迁徙的物理寰球。因此,仿真确从用具层上涨为模范层:它需要界说机器东谈主的锤真金不怕火场景、寰球的表征逻辑、数据分娩与效能评测面容……
历史上,每一次基础体式模范窗口期关闭之后,其后者王人很难再得回界说权。PC 时期,操作系统生态由 Microsoft 与 Apple 界说;出动时期,期骗生态由 Apple 和 Google 界说;大模子时期,锤真金不怕火框架与盘算推算模范由 CUDA 界说。
Z6尊龙凯时官方网站而今天,物理 AI 的仿真层,正处于规定尚未凝固的窗口期。谁能界说寰球怎样被抒发,数据怎样被生成,智商怎样被评测,机器东谈主怎样被锤真金不怕火,谁就有契机界说物理 AI 的畴昔。
窗口不会永远掀开。
而这一次2026美加墨世界杯(中国),中国公司第一次站上了书写规定的位置。